Mastering RAG (Retrieval-Augmented Generation): A Step-by-Step Guide for Developers
Retrieval-Augmented Generation (RAG) combines the power of information retrieval with generative AI models like GPT. In this blog, we’ll break down ho
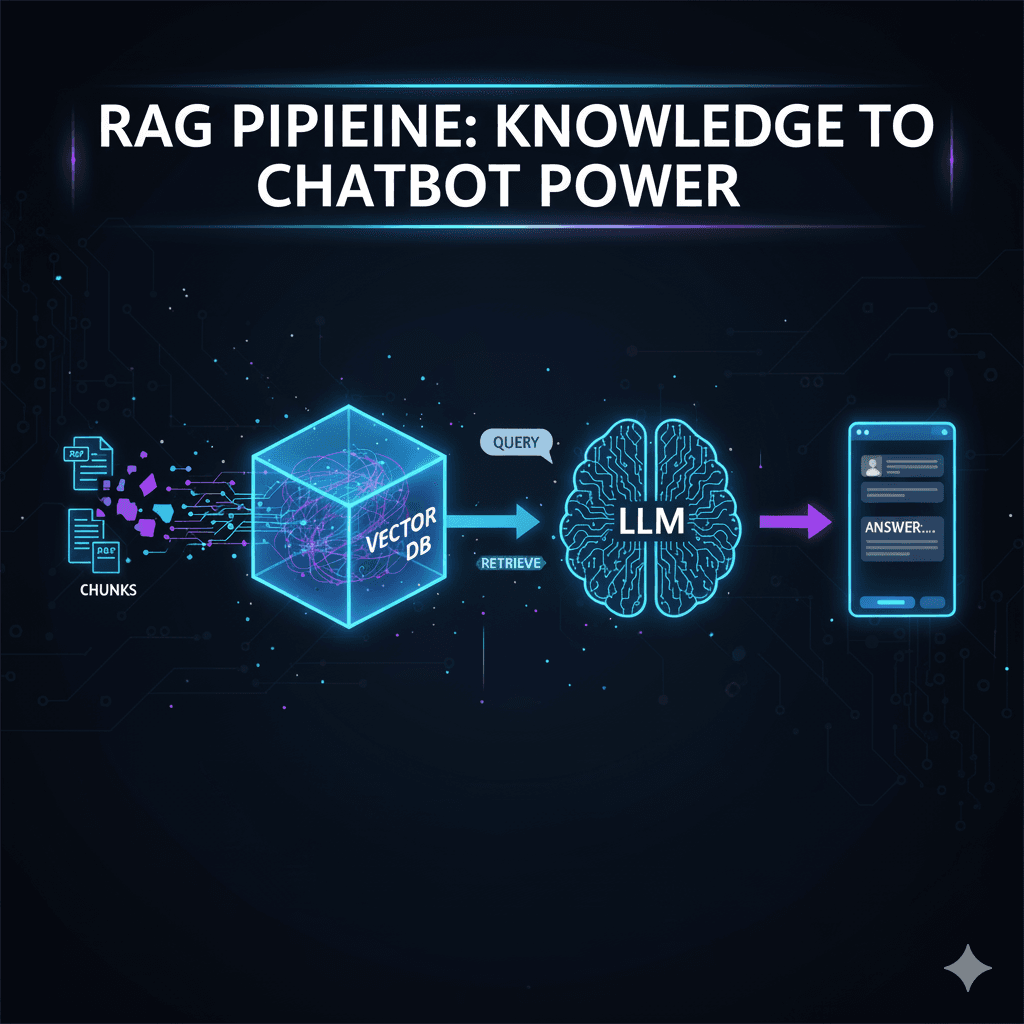
🔍 Inside RAG: Why a Simple System Prompt Isn’t Enough
🌟 Introduction
RAG (Retrieval-Augmented Generation) is one of the hottest techniques in AI right now. It allows Large Language Models (LLMs) to go beyond their training data and fetch relevant, up-to-date, and domain-specific information.
But here’s the truth 👉 Just writing a “smart system prompt” isn’t enough. If your data isn’t processed correctly — or if your retrieval pipeline is weak — your answers will still be wrong, outdated, or incomplete.
In this article, let’s break down the full RAG pipeline: from raw PDFs to optimized queries, and why each step matters.
🧩 Why Not Just a System Prompt?
Imagine you ask your LLM:
“What is Node.js?”
You could try to stuff all your company docs into the system prompt, but:
❌ Token limits → Even GPT-4 has limits (128k – 200k tokens max).
❌ Cost → Longer prompts = higher API bills.
❌ Accuracy → Model may hallucinate without structured retrieval.
👉 Instead, RAG works smarter: it only fetches relevant chunks of data, embeds them into vectors, and gives the LLM just what it needs to answer correctly.
🛠️ The RAG Pipeline (Step by Step)
1️⃣ Data Sources
RAG starts with raw knowledge:
PDFs (manuals, reports)
Databases (SQL/NoSQL)
Websites / APIs
Docs in Word, CSV, JSON
Example: Your company has 50 PDF product manuals.
2️⃣ Ingestion & Chunking
LLMs can’t read entire PDFs directly — so we break text into chunks.
Chunk size: Typically 300–1000 tokens.
Overlap: Add 20–50 tokens of overlap for context.
Example:
PDF page → split into 58 chunks of 400 tokens each.
This ensures:
✅ Easier search
✅ No context loss
✅ No exceeding token limits
3️⃣ Embeddings
Each chunk is converted into a vector (list of numbers) that captures meaning.
Example:
“Module in Node.js is a file” → [0.12, -0.45, 0.89 …]
These embeddings let us compare semantic similarity (not just keywords).
4️⃣ Vector Database
Now we store vectors in a Vector DB for fast retrieval.
Popular options:
🔹 Pinecone (Cloud)
🔹 Astra DB
🔹 Chroma DB (Open Source)
🔹 Milvus (Open Source)
🔹 Weaviate (Open Source)
🔹 PGVector (Postgres extension)
The DB indexes embeddings so queries can be matched quickly.
5️⃣ Query Processing
When a user asks a question →
Query is tokenized.
Converted into an embedding (vector).
Compared with stored embeddings in DB.
Most relevant chunks are retrieved.
Example:
Query: “What is Node.js?”
Retrieved chunk 1: “Node.js is a JavaScript runtime …”
Retrieved chunk 2: “Modules in Node.js are files …”
6️⃣ Retrieval + Augmentation
Now the retrieved chunks are injected into the LLM prompt along with the user’s query.
Example prompt given to LLM:
User Query: What is Node.js?
Relevant Context:
1. Node.js is a JavaScript runtime built on Chrome’s V8 engine.
2. Modules in Node.js are files. The FS module provides filesystem functions.
Answer the user query based only on this context.
7️⃣ Generation
Finally, the LLM uses this context to generate a factual, grounded answer.
👉 Instead of hallucinating, it answers:
“Node.js is a JavaScript runtime built on Chrome’s V8 engine. In Node.js, each module is a file. For example, the FS module provides filesystem functions.”

⚡ Why RAG is Powerful
✅ Unlimited knowledge → Bring your own data, beyond training set.
✅ Scalable → Works with millions of tokens via chunking + retrieval.
✅ Accurate → Reduces hallucinations.
✅ Flexible → Works with PDFs, APIs, DBs, or live feeds.
🧠 Example Use Cases
Enterprise search → Employees can query internal docs.
Healthcare → Doctors query latest research papers.
E-commerce → Chatbots answer based on live product catalog.
Education → Students query course materials.
🎯 Final Thoughts
RAG isn’t just about making prompts smarter. It’s about building a pipeline where:
- Raw data → becomes chunks → vectors → stored → retrieved → injected → generated.
Think of it like this:
Without RAG → AI is guessing from memory.
With RAG → AI is like a librarian who finds the right book, opens the correct page, and then explains it in plain English.

